Información general

Objetivos, características y beneficios
La arquitectura de interoperabilidad permite que productos software independientes funcionen juntos para prestar una funcionalidad, facilitando que varios productos software puedan comunicarse entre sí, aunque no hayan sido diseñados para ello. De esta forma, la Junta de Andalucía puede intercambiar información con otros organismos estatales o europeos.
Además, sirve como modelo para el intercambio y la sincronización de datos, garantizando que los procesos funcionen sin problemas y de manera eficiente, proporcionando una visión holística de la información, para facilitar la toma de decisiones informadas y la planificación estratégica.
Teniendo en cuenta lo anterior, se podría resumir que el objetivo de la arquitectura de interoperabilidad es actuar como traductor para que distintos sistemas o aplicaciones puedan comunicarse entre sí, proporcionando a la Junta de Andalucía una entrada única para la integración con las aplicaciones existentes, aislada de tecnologías, formatos o protocolos.
Las características de la arquitectura de interoperabilidad son:
- Servicios desacoplados: Actúa de mediador entre dos servicios que no son compatibles entre sí, manteniendo dichos servicios desacoplados e indiferentes de sus características técnicas para poder comunicarse.
- Información unificada: Permite unificar datos provenientes de varias fuentes a un formato común que será el que conozca y procese el resto del sistema.
- Aislamiento: Independiza la infraestructura de la Junta de Andalucía del exterior e incluso la permite dividir en diferentes secciones independientes a la propia organización, creando así silos independientes cada uno con sus propias características.
- Automatización: Reduce al mínimo el número de tareas manuales incorporando mecanismos de automatización de procesos.
Las principales ventajas de la arquitectura de interoperabilidad son las siguientes:
- Convivencia con sistemas legacy: Al facilitar la comunicación entre los diferentes componentes que interactúan en el flujo de un proceso, evita la necesidad inmediata de actualizar productos software obsoletos y permitir que esas aplicaciones sobrevivan durante un periodo más largo de tiempo intercambiando información con productos software actualizados.
- Aumento de la productividad: Al unificar la información permite aislar al desarrollador de complejos procesos de transformación manuales aumentando su productividad al permitirle centrarse en el negocio.
- Reducción de errores: Automatizar y centralizar tareas permite reducir los errores durante el desarrollo y evitar el código duplicado. Si se detecta un error en una tarea solo es necesario corregirlo en un punto para que se beneficie de ello todos los productos software afectados.
- Toma de decisiones más rápida: Puede proporcionar una visión más completa y precisa de los datos que permitirán tomar decisiones más informadas.
Principios
Partiendo de los principios generales definidos en la arquitectura global de servicio y que aplican en su totalidad a la arquitectura de microservicios, la arquitectura de referencia de interoperabilidad define un conjunto de principios específicos de aplicación en el desarrollo de integraciones y en el uso de la arquitectura
- Reutilizable
- Independencia y responsabilidad única
- Flexibilidad
- Orientado a servicios
(*) Puede consultarse el listado de Principios Tecnológicos Generales.
Reutilizable
Las integraciones deben diseñarse para su reutilización. Los componentes reutilizables reducen los costes de desarrollo y reducen el time-to-market para la entrega de nuevas funciones.
Independencia y responsabilidad única
Las integraciones deben ser independientes unas de otras. Esta independencia debe mantenerse tanto a nivel de negocio como a nivel técnico.
- Nivel de negocio: Una integración debe poner el foco en solo un elemento del negocio y encargarse de toda la gestión relativa a ese elemento. Es decir, debe tener solo una responsabilidad dentro del conjunto del sistema.
- Nivel técnico: Cada integración debe tener su propio ciclo de vida y poder actualizarse, levantarse y pararse sin afectar al resto del sistema. El nivel de independencia debe ser tal, que cualquier elemento del sistema debe de poder comunicarse con una integración sin necesidad de saber en qué tecnología, lenguaje o framework está implementado.
Flexibilidad
Una integración debe poder adaptarse con facilidad a las circunstancias, reduciendo la complejidad de implantación de nuevas características al mínimo. Además, debe poder adaptarse con rapidez a cualquier circunstancia que se produzca en el entorno productivo: picos de consumo, caída de servicios relacionados, cambios en la configuración.
Orientado a servicios
El objetivo de una integración es prestar un servicio y compartir el resultado de dicho servicio con el exterior. Por ello, las integraciones deben diseñarse para publicar servicios que pueden ser síncronos (api) o asíncronos (eventos).
Componentes
Los principales componentes que forman parte de una arquitectura de interoperabilidad son:
- Plataforma de integración
- Balanceador de carga
- Configuración centralizada
- Módulo de seguridad
- Conectores
- Colector observabilidad
- Mensajería
En el siguiente diagrama de arquitectura se muestran dichos componentes dentro de la arquitectura global:
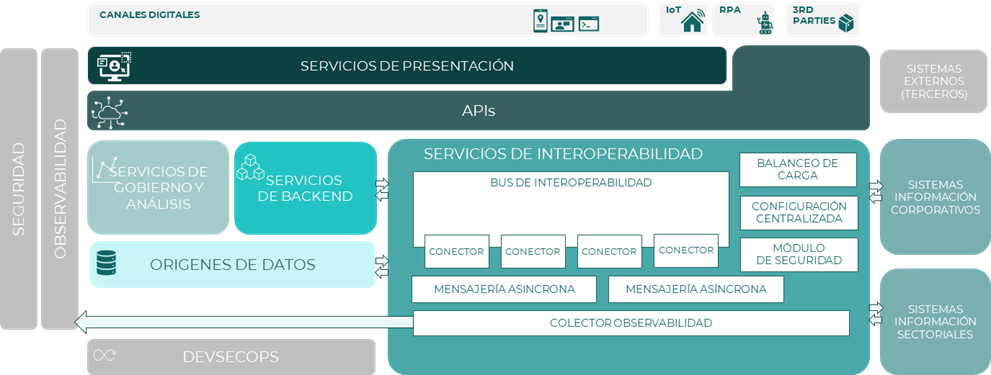
Bus de interoperabilidad
Este es el eje central donde ocurren todos los procesos de integración. Puede ser un bus de interoperabilidad como servicio local o desplegado en la nube. Puede contener un entorno gráfico para facilitar el desarrollo de integraciones.
Balanceador de carga
Un balanceador de carga permite repartir la carga de trabajo entre instancias que estén corriendo de un mismo servicio. Este componente identifica en tiempo real, que instancia es la más adecuada para responder a una petición, garantizando un nivel de rendimiento estable en el cluster. El balanceador de carga gestiona el tráfico si se añaden o eliminan instancias del servicio.
Configuración centralizada
Para facilitar la adaptación de los componentes a cualquier circunstancia que pueda producirse en tiempo real, la configuración debe estar centralizada y ser independiente del código desplegado, garantizando que los componentes puedan aceptar cambios de configuración en caliente sin necesidad de reinicio.
Conectores
Estos son componentes de software que permiten la integración y la comunicación entre diferentes sistemas y aplicaciones.
Módulo de seguridad
Dado que el bus de interoperabilidad es uno de los puntos de entrada a la red interna de la organización, existe un módulo de seguridad que vela por las comunicaciones con el exterior, salvaguardando la integridad de la infraestructura.
Colector de observabilidad
La observabilidad es el grado en el que comprendemos el estado interno o la condición de un sistema complejo basándonos solo en el conocimiento de sus salidas externas. Cuanto más observable sea un componente software, más rápida y precisa será su respuesta ante cualquier tipo de problema.
La observabilidad se basa en la generación, recolección y análisis de métricas, trazas y log:
- Métricas: Las métricas permiten gestionar la salud individual de un componente software.
- Trazas: Analizan el estado de una petición y nos permite comprobar si estas peticiones navegan correctamente a través de los diferentes componentes software.
- Logs: Mensajes que dan información variada sobre un componente software.
Un componente software debe cuidar la observabilidad en todo su ciclo de vida:
- En el desarrollo: Implantando componentes reutilizables y desarrollados expresamente para la ADA que le permitan generar trazas, métricas y log estandarizados y que se acojan a las normas y pautas definidas por la ADA.
- En el despliegue: Integrando la integración con los agentes centralizados que recogen las trazas, métricas y logs y los distribuye a las plataformas de monitorización.
- Durante el uso: Definiendo alertas y configurando cuadros de mandos que permitan a los responsables de calidad verificar el correcto funcionamiento de los componentes software en tiempo real.
Mensajería
El sistema de mensajería permite la conexión asíncrona entre dos sistemas o aplicaciones, tanto para mensajería de ida (envío) como de vuelta (recepción de respuesta).
Este sistema también permitirá la comunicación punto a punto como la comunicación entre múltiples orígenes y destinatarios.
Nota: El componente de mensajería asíncrona se detalla con mayor profundidad en el documento de definición de la arquitectura de referencia orientada a eventos.
Patrones de arquitectura y diseño
A continuación, se describirá el conjunto de patrones que aplican en el diseño y construcción de servicios de interoperabilidad. La utilización de estos patrones, son la solución para construir elementos que cumplan con los principios ya descritos usando para ello los componentes definidos en el apartado anterior.
Patrones de integración empresarial
Los patrones de integración son claves para conectar aplicaciones con sistemas heterogéneos. A lo largo de los años, se ha visto que la mayoría de las integraciones tienen muchas similitudes, lo que inició un conjunto de estándares ampliamente aceptados en la arquitectura de interoperabilidad. La mayoría de estos estándares se describen en el Catálogo de Patrones de Integración Empresarial (EIP – Enterprise Integration Patterns).
Existe más de un enfoque para integrar aplicaciones, con un mismo planteamiento del problema (la necesidad de integrar aplicaciones) y contextos muy similares. Cada enfoque se basa en el anterior, buscando más sofisticación para abordar las deficiencias de sus predecesores.
No consiste en elegir “el estilo a utilizar siempre”, sino en elegir el mejor estilo para una integración particular. Cada estilo tiene sus ventajas y desventajas. Dos aplicaciones pueden integrarse utilizando múltiples estilos de modo que cada punto de integración aproveche el estilo que mejor le convenga. Una aplicación puede usar diferentes estilos para integrarse con diferentes aplicaciones, para elegir el estilo que funcione mejor para la otra.
File Transfer
En este patrón el componente software genera ficheros que contienen la información que debe compartir a otro componente. La plataforma de integración tiene la responsabilidad de transformar estos ficheros a diferentes formatos y enviar los ficheros a intervalos definidos según las necesidades del negocio.
Este patrón puede implementarse en ambos sentidos, es decir, un componente puede generar ficheros que serán compartidos a través de la plataforma de integración y consumir ficheros que la plataforma de integración le envía de otros componentes software.

Principios que aplican:
- Independencia y responsabilidad única
- Orientado a servicios
- Flexibilidad
- Desacoplamiento de componentes
Referencia: File Transfer
Remote Procedure Invocation (RPI)
Este patrón determina que si un componente software necesita información gestionada por otro componente debe solicitarla usando el mecanismo de invocación a procedimiento remoto (RPI). De esta forma, cada componente es responsable de sus datos y puede modificarlos o compartirlos bajo demanda.
Cuando este patrón se implemente para comunicarse con componentes externos a la Junta de Andalucía o componentes internos pero incompatibles entre sí, esta comunicación deberá pasar por el Bus de interoperabilidad que se encargará de hacer las transformaciones necesaria en la petición y la respuesta y aplicar los mecanismos de seguridad necesarios si la comunicación será con un componente externo.

Principios que aplican:
- Independencia y responsabilidad única
- Orientado a servicios
- Flexibilidad
- Desacoplamiento de componentes
Referencia: Remote Procedure Invocation (RPI)
Shared database
Este patrón evita los problemas de sincronización permitiendo que varios componentes tengan una base de datos común y de esta forma puedan compartir información.
Dado el acoplamiento que introduce este patrón, antes de aplicarlo, debe analizarse si el caso de uso requiere de unos datos tan actualizados que hace imposible la sincronización de los componentes por otros procedimientos. Además, se debe estudiar qué información debe ser compartida y cómo tiene que diseñarse el modelo de datos compartido que acogerá esa información.
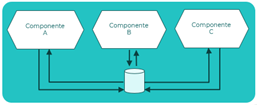
Principios que aplican:
- Fuente única de verdad
- Simplicidad
- Agilidad
Referencia: Shared database
Messaging
Este patrón permite compartir la información entre varios componentes usando para ello mensajería asíncrona. De esta forma cada componente puede procesar la petición de información a su ritmo sin bloquear al componente que la está esperando.
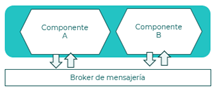
Principios que aplican:
- Independencia y responsabilidad única
- Orientado a servicios
- Flexibilidad
- Desacoplamiento de componentes
Referencia: Messaging
Patrones para la resiliencia de integraciones
Circuit breaker
En un sistema distribuido, cuando un servicio hace una llamada síncrona a otro servicio existe un permanente riesgo de fallo. Como el cliente y el servicio están en procesos separados, un servicio puede no responder a tiempo la solicitud de un cliente porque está caído por fallo o mantenimiento o por existir problemas en la red que ralentizan o hagan imposible la comunicación. Dado que habitualmente el cliente está bloqueado mientras espera la respuesta, cualquier problema en un servicio puede generar un fallo en cascada en todo el sistema.
Este tipo de problemas se gestiona mediante la combinación de una serie de mecanismos:
- Indisponibilidad de la red: Estableciendo timeouts que impidan el bloqueo indefinido de un cliente al no obtener respuesta del servicio.
- Limitación de peticiones a un servicio: Limitando el número de peticiones por segundo que puede recibir un servicio para evitar que se sature y deje de funcionar correctamente.
- Implementación del patrón circuit breaker.
Este patrón mide el número de peticiones procesadas y establece la relación de error aceptable en los servicios invocados. Cuando se sobrepasa esta relación, se abre el circuito y se interviene inmediatamente redireccionando las peticiones al servicio que no está disponible y actuando antes de que se produzca el error.
Periódicamente el circuit breaker controla si el servicio vuelve a estar disponible. Cuando el servicio está disponible de nuevo, cierra el circuit breaker y dejar que el sistema funcione con normalidad.
Principios que aplican:
- Resiliencia sobre recuperación
Referencia: Circuit breaker
Patrones de observabilidad
Application metrics
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia: Application metrics
Audit logging
Cada log identifica al usuario, la acción que está realizando y el objeto de negocio.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia: Audit logging
Distributed tracing
Este patrón permite seguir el recorrido de una petición a través de todos los servicios por los que pasa, permitiendo ver los servicios internos y externos con los que la petición ha interaccionado.
Principios que aplican:
- Calidad del servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia:
Exception tracking
Cuando se produce una excepción, es importante identificar la causa raíz. Una excepción es un síntoma de que algo no marcha bien en un servicio. La forma tradicional de visualizar las excepciones es mirando los logs, sin embargo, una aproximación mejor es usar un servicio de seguimiento de excepciones.
Este patrón configura un servicio para reportar excepciones que permite hacer seguimiento de las excepciones duplicadas, alertas generadas y gestionar el manejo de excepciones.
Principios que aplican:
- Calidad del servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia:
Health check API
Este patrón implementa, publicando un endpoint, un mecanismo para que una integración pueda comunicar al resto de servicios si está preparado para recibir peticiones.
Principios que aplican:
- Calidad del servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia:
Log aggregation
Este patrón recoge los logs distribuidos en diferentes integraciones y los muestra unificados para facilitar el seguimiento y el mantenimiento de las aplicaciones.
Principios que aplican:
- Calidad del servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Referencia:
Pila tecnológica
A continuación, se muestra un diagrama y se resume la pila tecnológica que se usará como solución a los componentes necesarios para una arquitectura de interoperabilidad.
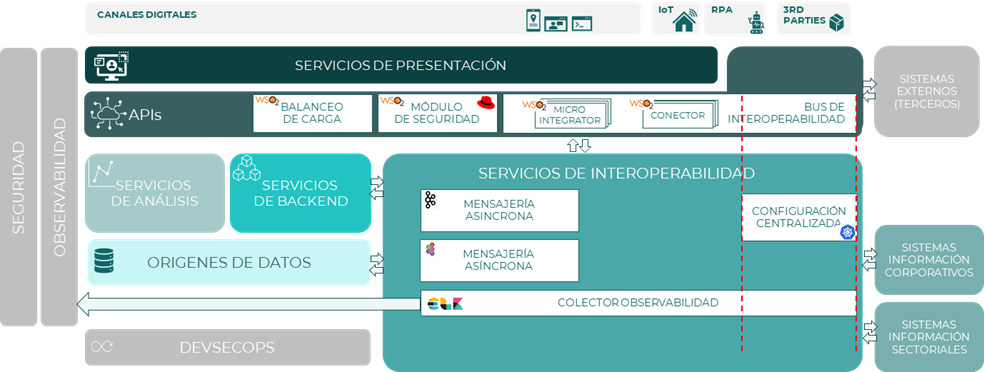
| Componente | Solución | Descripción |
|---|---|---|
| BUS de Interoperabilidad | WSO2 Micro Integrator | Es el runtime que nos permitirá la creación de APIs, servicios SOAP o servicios de acceso a base de datos. Está basado en configuraciones xml. Incluye una herramienta CLI, un operador de Kubernetes, panel de monitoreo y cientos de conectores. |
| WSO2 Integration Studio | Es el entorno de desarrollo gráfico de arrastrar y soltar. Incluye una paleta de herramientas visual, la opción de importar e incluir conectores y vistas de propiedades para configuraciones complejas. | |
| Conector (WSO2 EI Connectors) | WSO2 proporciona un marketplace con gran cantidad de conectores para integrarse con APIs de terceros, a la vez que proporciona métodos y lógica para tratar con productos de terceros. | |
| Balanceo de carga | WSO2 Control Plane | Componente que permite balancear los accesos para asegurar que todas las réplicas de las integraciones tengan una carga de trabajo similar. Se utilizará el servicio de balanceo que se configura con el patrón de despliegue 3 de API Manager + Micro Integrator. |
| Configuración centralizada | Kubernetes | Componente que permite gestionar la configuración de una integración de forma centralizada desde la plataforma de Kubernetes. |
| Módulo de seguridad | WSO2 Key Manager | WSO2 Key Manager es el módulo donde se realizan las validaciones de seguridad, generaciones de claves y se toman decisiones sobre el límite de peticiones. |
| Red Hat build of Keycloak | Red Hat build of Keycloak es una herramienta para la gestión de identidades y accesos basada en keycloak. | |
| Observabilidad | ELK | Componente que permite gestionar la observabilidad. Se utilizará el stack ELK con Elastic, Logstash y Kibana |
| Mensajería | Apache Kafka | Se utilizará la versión Apache Kafka como broker de mensajería. |
| ActiveMQ Artemis | Se utilizará ActiveMQ Artemis como sistema de colas. |
Escenarios de aplicación
A continuación, se presentan algunos escenarios donde tienen cabida la arquitectura de interoperabilidad.
Escenario 1: Fuente de datos para aplicación corporativa
Escenario
En este primer escenario se expone la necesidad de compartir datos desde distintas fuentes a una aplicación corporativa.
“Existe en la organización una aplicación que lleva mucho tiempo funcionando, que recoge datos de una tabla en base de datos / una cola / un directorio / un ftp, y realiza un procesamiento con ellos. Cuando se desarrolló la aplicación, había una única fuente de datos y actualmente ya hay aplicaciones existentes de proveedores externos y otras nuevas que se van a desarrollar que también tienen que servir como fuentes de datos, algunas estarán alojadas dentro de la organización y otras se tendrán que conectar desde fuera.”
Descripción
Lo primero que vemos es que habrá aplicaciones tanto internas como externas, que no podrán conectarse directamente a la localización para dejar los datos. Además, habrá múltiples aplicaciones que generen datos, con sus propios equipos de desarrollo, lo que puede provocar tantas formas de enviar datos como aplicaciones se vayan a desarrollar. Y también hay aplicaciones ya existentes de otros proveedores con su propio formato de envío de datos.
Para dar solución a los problemas anteriormente mencionados, la arquitectura de interoperabilidad proporciona patrones para facilitar la comunicación entre orígenes con distintos formatos de datos a enviar y destinos (con un formato predefinido a recibir), aislando completamente a los orígenes sobre el tipo y localización donde dejar los datos (base de datos, ficheros, ftps, colas, …).
Se creará una integración haciendo uso del patrón Normalizador (normalizer). Este patrón hace uso del patrón enrutador de mensajes (message router) para enrutar los mensajes de entrada al traductor de mensajes (message translator) que le corresponde en función de quién sea el productor de los datos. Estos traductores transformarán el mensaje recibido al formato correcto que espera la aplicación de destino y lo enviará a la localización requeridas por la aplicación que consume los datos (ya sea una base de datos, carpeta o sistema de mensajería).
Patrones
- Normalizer
- Message router
- Message translator
Escenario 2: Enriquecer mensajes con datos privados internos de la organización
Escenario
El segundo escenario que se expone es la necesidad de obtención aportar datos almacenados en nuestra organización a los que no se puede acceder de forma externa, para dotar de información extra a un mensaje recibido de una aplicación externa y que tiene que llegar a otra aplicación interna de la organización.
“Existe una aplicación móvil desarrollada, que tiene que enviar datos privados sanitarios de los usuarios a una aplicación interna de la organización. La aplicación no posee todos los datos necesarios y no existe forma de que pueda obtenerlos por protección de datos. Es necesario un punto intermedio que sea capaz de enriquecer ese mensaje de entrada recibido desde la aplicación móvil, con los datos privados para mandárselos a la aplicación destino”.
Descripción
Si revisamos los distintos patrones de integración existente, podemos observar que este problema no es nuevo y que ya tiene solución. El patrón Content Enricher (Enriquecedor de contenidos).
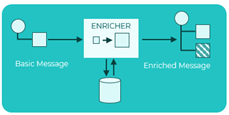
El patrón utiliza información dentro del mensaje entrante (por ejemplo, campos clave) para recuperar datos de una fuente de datos. Después de que recupere los datos necesarios del recurso, agrega los datos al mensaje. La información original del mensaje entrante puede transferirse al mensaje resultante o puede que ya no sea necesaria, según las necesidades específicas de la aplicación receptora.
Patrones
- Content Enricher
Escenario 3: Redirección de datos a aplicaciones en función de su contenido
Escenario
En este tercer escenario se presenta la necesidad de enviar datos a distintas aplicaciones destino en función del contenido del mensaje recibido.
“Existe un conjunto de aplicaciones en la organización que envían datos en tiempo real a la organización. Aunque son datos de cosas distintas, los mensajes que envían todas las aplicaciones tienen la misma estructura. En función de la tipología del mensaje enviado, indicado en uno de los campos, éste debería de ser entregado a una aplicación concreta”.
Descripción
De nuevo, si revisamos los patrones de integración existentes, veremos que ya existe un patrón que soluciona este problema de forma sencilla, el Content-Based Router (Enrutador basado en contenido).
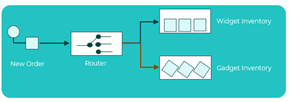
El enrutador examina el contenido del mensaje y lo envía a un destino diferente según los datos contenidos en el mensaje. El enrutamiento puede basarse distintos criterios, como la existencia de campos, valores de campos específicos, etc. Se debe tener especial cuidado para que la función de enrutamiento sea fácil de mantener, ya que el enrutador puede convertirse en un punto de mantenimiento frecuente. En escenarios de integración más sofisticados, el enrutador basado en contenido puede adoptar la forma de un motor de reglas configurable que calcula el canal de destino en función de un conjunto de reglas configurables.Patrones
- Content based router
Escenario 4: Envío de datos pesados de forma asíncrona
Escenario
En este cuarto escenario se presenta la necesidad de enviar grandes cantidades de información entre dos aplicaciones.
“Existe una serie de sistemas tramitadores que envían expedientes que tienen que ser almacenados en @rchiva, un sistema común para la gestión integrada de los documentos. Los expedientes constan de gran cantidad de datos por lo que se necesita que el tramitador no se tenga que quedar esperando a que se guarden y también necesita de alguna forma confirmación de que han sido almacenados en @rchiva.”
Descripción
Dado que se indica que los sistemas tramitadores no se tienen que quedar a la espera, ya nos indica que debemos crear un sistema asíncrono. Además, será necesario crear un punto de comprobación de estado para verificar que el expediente enviado ha sido almacenado en @archiva.
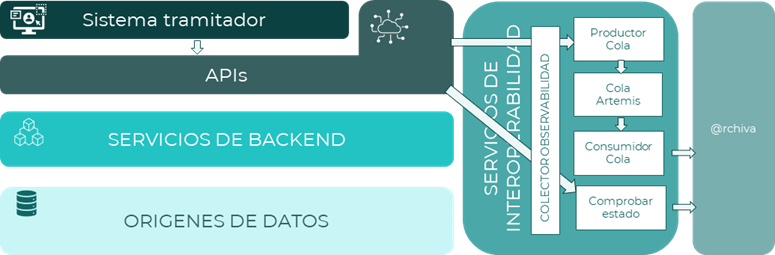
Haciendo uso del esquema anterior propuesto como solución a este escenario, se puede ver que el sistema tramitador, a través de un API, envía los expedientes a un servicio productor que, mediante un patrón de filtrado, será capaz de enviar a una cola concreta el mensaje con el expediente recibido. Se hará uso de una cola Artemis ya que tiene más capacidad para mantener mensajes de gran tamaño que un bróker de Kafka.
Se creará un servicio de consumo de mensajes de la que, cada cierto tiempo, consuma los mensajes específicos de expedientes que haya en la cola y los envíe al sistema @rchiva.
Además, se creará una segunda integración que permita consulta a @rchiva sobre un expediente concreto para que el tramitador pueda conocer si ya ha sido almacenado.
- Message router
- Message endpoint
Referencias
- Referencias técnicas: